
Le clustering et la réplication sont des techniques essentielles pour améliorer la disponibilité, la performance et la résilience des bases de données. Dans cet article, nous explorerons ces deux concepts et discuterons de leurs avantages et de leurs cas d’utilisation.
1. Clustering : Améliorer la Disponibilité et la Performance
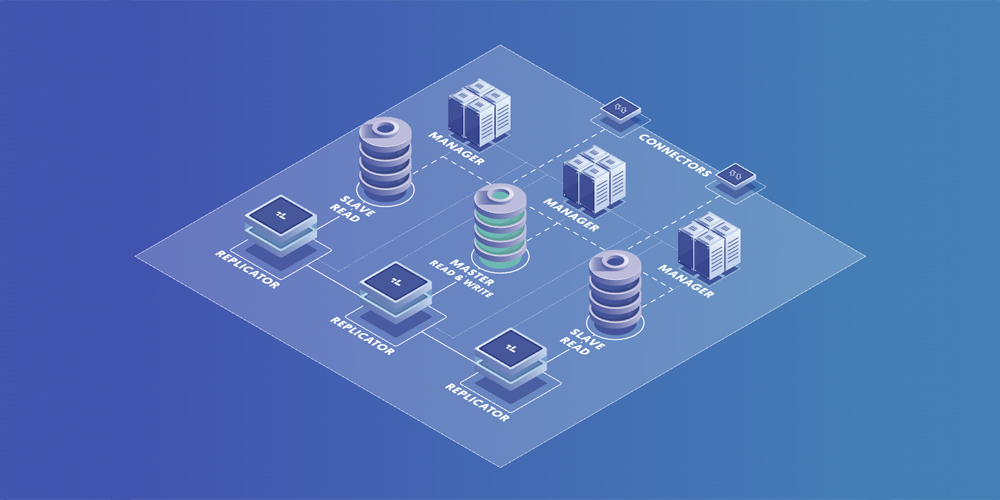
Le clustering consiste à regrouper plusieurs serveurs pour former un système unique, capable de gérer efficacement les requêtes et de garantir une haute disponibilité. Les clusters de bases de données peuvent être configurés de différentes manières, notamment en utilisant des solutions comme Galera, Percona XtraDB Cluster, ou simplement en configurant un cluster de réplication standard avec MySQL/MariaDB. Ces solutions permettent de répartir la charge entre les serveurs, d’assurer une tolérance aux pannes et d’optimiser les performances en permettant l’exécution parallèle des requêtes.
2. Réplication : Duplication des Données pour la Redondance et la Performance
La réplication consiste à copier les données d’une base de données vers une ou plusieurs autres bases de données, généralement sur des serveurs distants. Cette technique permet d’améliorer la disponibilité des données en cas de panne d’un serveur, ainsi que de répartir la charge des requêtes entre les différents serveurs répliqués. La réplication peut être configurée de différentes manières, notamment en utilisant la réplication synchrone ou asynchrone, et peut être mise en œuvre avec diverses bases de données, telles que MySQL, PostgreSQL, et d’autres.
3. Cas d’Utilisation de Clustering et Réplication
Les techniques de clustering et de réplication sont largement utilisées dans une variété de cas d’utilisation, notamment pour les applications web à forte charge, les applications critiques nécessitant une haute disponibilité, et les systèmes de reporting et d’analyse nécessitant des performances élevées. En combinant clustering et réplication, les organisations peuvent mettre en place des infrastructures robustes et évolutives, capables de répondre aux exigences de leurs applications les plus critiques.
4. Comment Choisir entre Clustering et Réplication
Le choix entre clustering et réplication dépendra des besoins spécifiques de votre application, de vos contraintes de performance, de disponibilité et de budget. Dans certains cas, une simple configuration de réplication peut suffire à améliorer la disponibilité des données, tandis que dans d’autres cas, un cluster de bases de données distribuées sera nécessaire pour garantir la performance et la résilience. Il est recommandé de consulter des experts en bases de données pour évaluer vos besoins et déterminer la meilleure solution pour votre infrastructure.
Conclusion
Le clustering et la réplication sont des techniques essentielles pour optimiser la disponibilité, la performance et la résilience des bases de données. Que vous choisissiez le clustering, la réplication ou une combinaison des deux, il est important de comprendre les avantages et les limitations de chaque approche et de les adapter à vos besoins spécifiques. N’hésitez pas à contacter notre équipe d’experts pour obtenir de l’aide dans la conception et la mise en œuvre d’une architecture de bases de données robuste et évolutive.